Proper study guides for Renovate Microsoft Perform Big Data Engineering on Microsoft Cloud Services (beta) certified begins with Microsoft 70-776 preparation products which designed to deliver the Approved 70-776 questions by making you pass the 70-776 test at your first time. Try the free 70-776 demo right now.
NEW QUESTION 1
DRAG DROP
You have a Microsoft Azure Stream Analytics solution that captures website visits and user interactions on the website.
You have the sample input data described in the following table.
You have the sample output described in the following table.
How should you complete the script? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.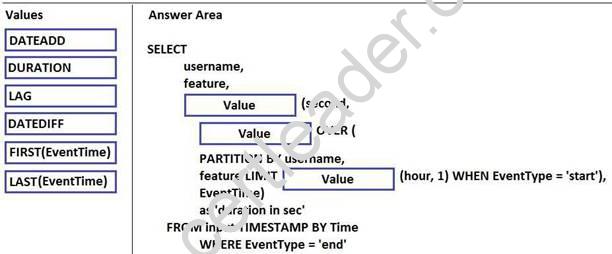
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
References:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-stream-analytics-query- patterns
NEW QUESTION 2
You plan to deploy a Microsoft Azure Stream Analytics job to filter multiple input streams from IoT devices that have a total data flow of 30 MB/s.
You need to calculate how many streaming units you require for the job. The solution must prevent lag.
What is the minimum number of streaming units required?
- A. 3
- B. 10
- C. 30
- D. 300
Answer: C
NEW QUESTION 3
DRAG DROP
You plan to develop a solution for real-time sentiment analysis of Twitter data.
You need to create a Microsoft Azure Stream Analytics job query to count the number of tweets during a period.
Which Window function should you use for each requirement? To answer, drag the appropriate functions to the correct requirements. Each function may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
References:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-window-functions
NEW QUESTION 4
You are designing a solution that will use Microsoft Azure Data Lake Store.
You need to recommend a solution to ensure that the storage service is available if a regional outage occurs. The solution must minimize costs.
What should you recommend?
- A. Create two Data Lake Store accounts and copy the data by using Azure Data Factory.
- B. Create one Data Lake Store account that uses a monthly commitment package.
- C. Create one read-access geo-redundant storage (RA-GRS) account and configure a Recovery Services vault.
- D. Create one Data Lake Store account and create an Azure Resource Manager template that redeploys the services to a different region.
Answer: D
NEW QUESTION 5
You have a file in a Microsoft Azure Data Lake Store that contains sales data. The file contains sales amounts by salesperson, by city, and by state.
You need to use U-SQL to calculate the percentage of sales that each city has for its respective state. Which code should you use?

- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: A
NEW QUESTION 6
You have a Microsoft Azure Data Lake Analytics service.
You need to store a list of milltiple-character string values in a single column and to use a cross apply explode expression to output the values.
Which type of data should you use in a U-SQL query?
- A. SQL.MAP
- B. SQL.ARRAY
- C. string
- D. byte [ ]
Answer: B
NEW QUESTION 7
You ingest data into a Microsoft Azure event hub.
You need to export the data from the event hub to Azure Storage and to prepare the data for batch processing tasks in Azure Data Lake Analytics.
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Run the Avro extractor from a U-SQL script.
- B. Create an Azure Storage account.
- C. Add a shared access policy.
- D. Enable Event Hubs Archive.
- E. Run the CSV extractor from a U-SQL script.
Answer: BD
NEW QUESTION 8
You have a Microsoft Azure SQL data warehouse. You have an Azure Data Lake Store that contains data from ORC, RC, Parquet, and delimited text files.
You need to load the data to the data warehouse in the least amount of time possible. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Use Microsoft SQL Server Integration Services (SSIS) to enumerate from the Data Lake Store by using a for loop.
- B. Use AzCopy to export the files from the Data Lake Store to Azure Blob storage.
- C. For each file in the loop, export the data to Parallel Data Warehouse by using a Microsoft SQL Server Native Client destination.
- D. Load the data by executing the CREATE TABLE AS SELECT statement.
- E. Use bcp to import the files.
- F. In the data warehouse, configure external tables and external file formats that correspond to the Data Lake Store.
Answer: DF
Explanation:
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-load-from-azure-data-lake-store
NEW QUESTION 9
You use Microsoft Azure Data Lake Store as the default storage for an Azure HDInsight cluster.
You establish an SSH connection to the HDInsight cluster.
You need to copy files from the HDInsight cluster to the Data LakeStore. Which command should you use?
- A. AzCopy
- B. hdfs dfs
- C. hadoop fs
- D. AdlCopy
Answer: D
NEW QUESTION 10
HOTSPOT
You need to create a Microsoft Azure SQL data warehouse named dw1 that supports up to 10 TB of data. How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 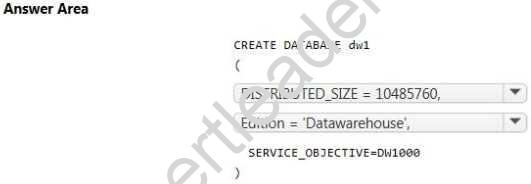
NEW QUESTION 11
Note: This question is part of a series of questions that present the same scenario. Each question in
the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are troubleshooting a slice in Microsoft Azure Data Factory for a dataset that has been in a waiting state for the last three days. The dataset should have been ready two days ago.
The dataset is being produced outside the scope of Azure Data Factory. The dataset is defined by using the following JSON code.
You need to modify the JSON code to ensure that the dataset is marked as ready whenever there is data in the data store.
Solution: You change the external attribute to true. Does this meet the goal?
- A. Yes
- B. No
Answer: A
Explanation:
References:
https://docs.microsoft.com/en-us/azure/data-factory/v1/data-factory-create-datasets
NEW QUESTION 12
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
- A. adataset
- B. a gateway
- C. a pipeline
- D. a linked service
Answer: A
NEW QUESTION 13
Note: This question is part of a series of questions that present the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract, transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
On the on-premises network, you have a Data Management Gateway.
Some source data is stored in Azure Blob storage. Some source data is stored on an on-premises Microsoft SQL Server instance. The instance has a table named Table1.
After data is processed by using AzureDF, the data must be archived and accessible forever. The archived data must meet a Service Level Agreement (SLA) for availability of 99 percent. If an Azure region fails, the archived data must be available for reading always. The storage solution for the archived data must minimize costs.
End of repeated scenario.
You need to configure an activity to move data from blob storage to AzureDW. What should you create?
- A. a pipeline
- B. a linked service
- C. an automation runbook
- D. a dataset
Answer: A
Explanation:
References:
https://docs.microsoft.com/en-us/azure/data-factory/v1/data-factory-azure-blob-connector
NEW QUESTION 14
You are implementing a solution by using Microsoft Azure Data Lake Analytics. You have a dataset that contains data-related to website visits.
You need to combine overlapping visits into a single entry based on the timestamp of the visits. Which type of U-SQL interface should you use?
- A. IExtractor
- B. IReducer
- C. Aggregate
- D. IProcessor
Answer: C
NEW QUESTION 15
You are using Cognitive capabilities in U-SQL to analyze images that contain different types of objects.
You need to identify which objects might be people.
Which two reference assemblies should you use? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. ExtPython
- B. ImageCommon
- C. ImageTagging
- D. ExtR
- E. FaceSdk
Answer: BC
NEW QUESTION 16
DRAG DROP
You have an on-premises Microsoft SQL Server instance named Instance1 that contains a database named DB1.
You have a Data Management Gateway named Gateway1.
You plan to create a linked service in Azure Data Factory for DB1.
You need to connect to DB1 by using standard SQL Server Authentication. You must use a username of User1 and a password of P@$$w0rd89.
How should you complete the JSON code? TO answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
References:
https://github.com/uglide/azure-content/blob/master/articles/data-factory/data-factory-move-data-between-onprem-and-cloud.md
NEW QUESTION 17
HOTSPOT
You have a Microsoft Azure Data Lake Analytics service.
You have a file named Employee.tsv that contains data on employees. Employee.tsv contains seven columns named EmpId, Start, FirstName, LastName, Age, Department, and Title.
You need to create a Data Lake Analytics jobs to transform Employee.tsv, define a schema for the data, and output the data to a CSV file. The outputted data must contain only employees who are in the sales department. The Age column must allow NULL.
How should you complete the U-SQL code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.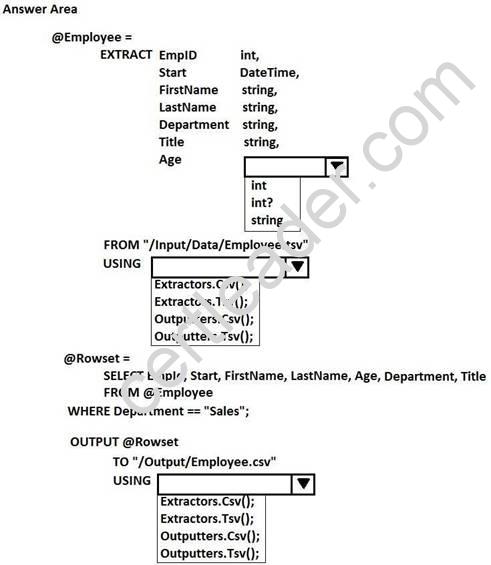
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
References:
https://docs.microsoft.com/en-us/azure/data-lake-analytics/data-lake-analytics-u-sql-get-started
NEW QUESTION 18
You have a Microsoft Azure Data Lake Analytics service.
You need to write a U-SQL query to extract from a CSV file all the users who live in Boston, and then to save the results in a new CSV file.
Which U-SQL script should you use?



- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: A
NEW QUESTION 19
Note: This question is part of a series of questions that present the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract, transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
On the on-premises network, you have a Data Management Gateway.
Some source data is stored in Azure Blob storage. Some source data is stored on an on-premises Microsoft SQL Server instance. The instance has a table named Table1.
After data is processed by using AzureDF, the data must be archived and accessible forever. The archived data must meet a Service Level Agreement (SLA) for availability of 99 percent. If an Azure region fails, the archived data must be available for reading always. The storage solution for the archived data must minimize costs.
End of repeated scenario.
You need to define the schema of Table1 in AzureDF. What should you create?
- A. a gateway
- B. a linked service
- C. a dataset
- D. a pipeline
Answer: C
NEW QUESTION 20
DRAG DROP
You need to load data from Microsoft Azure Data Lake Store to Azure SQL Data Warehouse by using Transact-SQL.
In which sequence should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 
NEW QUESTION 21
You are developing an application that uses Microsoft Azure Stream Analytics.
You have data structures that are defined dynamically.
You want to enable consistency between the logical methods used by stream processing and batch processing.
You need to ensure that the data can be integrated by using consistent data points. What should you use to process the data?
- A. a vectorized Microsoft SQL Server Database Engine
- B. directed acyclic graph (DAG)
- C. Apache Spark queries that use updateStateByKey operators
- D. Apache Spark queries that use mapWithState operators
Answer: D
NEW QUESTION 22
......
Thanks for reading the newest 70-776 exam dumps! We recommend you to try the PREMIUM Certshared 70-776 dumps in VCE and PDF here: https://www.certshared.com/exam/70-776/ (91 Q&As Dumps)