Our pass rate is high to 98.9% and the similarity percentage between our DP-200 study guide and real exam is 90% based on our seven-year educating experience. Do you want achievements in the Microsoft DP-200 exam in just one try? I am currently studying for the Microsoft DP-200 exam. Latest Microsoft DP-200 Test exam practice questions and answers, Try Microsoft DP-200 Brain Dumps First.
Free demo questions for Microsoft DP-200 Exam Dumps Below:
NEW QUESTION 1
A company has a SaaS solutions that will uses Azure SQL Database with elastic pools. The solution will have a dedicated database for each customer organization Customer organizations have peak usage at different periods during the year.
Which two factors affect your costs when sizing the Azure SQL Database elastic pools? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- A. maximum data size
- B. number of databases
- C. eDTUs consumption
- D. number of read operations
- E. number of transactions
Answer: AC
NEW QUESTION 2
You need to ensure that Azure Data Factory pipelines can be deployed. How should you configure authentication and authorization for deployments? To answer, select the appropriate options in the answer choices.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
The way you control access to resources using RBAC is to create role assignments. This is a key concept to understand – it’s how permissions are enforced. A role assignment consists of three elements: security principal, role definition, and scope.
Scenario:
No credentials or secrets should be used during deployments
Phone-based poll data must only be uploaded by authorized users from authorized devices Contractors must not have access to any polling data other than their own
Access to polling data must set on a per-active directory user basis References:
https://docs.microsoft.com/en-us/azure/role-based-access-control/overview
NEW QUESTION 3
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You need to configure data encryption for external applications.
Solution:
1. Access the Always Encrypted Wizard in SQL Server Management Studio
2. Select the column to be encrypted
3. Set the encryption type to Deterministic
4. Configure the master key to use the Windows Certificate Store
5. Validate configuration results and deploy the solution Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
Use the Azure Key Vault, not the Windows Certificate Store, to store the master key.
Note: The Master Key Configuration page is where you set up your CMK (Column Master Key) and select the key store provider where the CMK will be stored. Currently, you can store a CMK in the Windows certificate store, Azure Key Vault, or a hardware security module (HSM).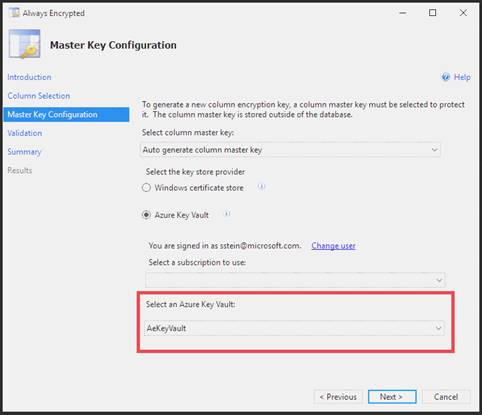
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-always-encrypted-azure-key-vault
NEW QUESTION 4
You plan to use Microsoft Azure SQL Database instances with strict user access control. A user object must:  Move with the database if it is run elsewhere Be able to create additional users
Move with the database if it is run elsewhere Be able to create additional users
You need to create the user object with correct permissions.
Which two Transact-SQL commands should you run? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. ALTER LOGIN Mary WITH PASSWORD = 'strong_password';
- B. CREATE LOGIN Mary WITH PASSWORD = 'strong_password';
- C. ALTER ROLE db_owner ADD MEMBER Mary;
- D. CREATE USER Mary WITH PASSWORD = 'strong_password';
- E. GRANT ALTER ANY USER TO Mary;
Answer: CD
Explanation:
C: ALTER ROLE adds or removes members to or from a database role, or changes the name of a user-defined database role.
Members of the db_owner fixed database role can perform all configuration and maintenance activities on the database, and can also drop the database in SQL Server.
D: CREATE USER adds a user to the current database.
Note: Logins are created at the server level, while users are created at the database level. In other words, a login allows you to connect to the SQL Server service (also called an instance), and permissions inside the database are granted to the database users, not the logins. The logins will be assigned to server roles (for example, serveradmin) and the database users will be assigned to roles within that database (eg. db_datareader, db_bckupoperator).
References:
https://docs.microsoft.com/en-us/sql/t-sql/statements/alter-role-transact-sql https://docs.microsoft.com/en-us/sql/t-sql/statements/create-user-transact-sql
NEW QUESTION 5
You need to set up access to Azure SQL Database for Tier 7 and Tier 8 partners.
Which three actions should you perform in sequence? To answer, move the appropriate three actions from the list of actions to the answer area and arrange them in the correct order.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Tier 7 and 8 data access is constrained to single endpoints managed by partners for access Step 1: Set the Allow Azure Services to Access Server setting to Disabled
Set Allow access to Azure services to OFF for the most secure configuration.
By default, access through the SQL Database firewall is enabled for all Azure services, under Allow access to Azure services. Choose OFF to disable access for all Azure services.
Note: The firewall pane has an ON/OFF button that is labeled Allow access to Azure services. The ON setting allows communications from all Azure IP addresses and all Azure subnets. These Azure IPs or subnets might not be owned by you. This ON setting is probably more open than you want your SQL Database to be. The virtual network rule feature offers much finer granular control.
Step 2: In the Azure portal, create a server firewall rule Set up SQL Database server firewall rules
Server-level IP firewall rules apply to all databases within the same SQL Database server. To set up a server-level firewall rule: In Azure portal, select SQL databases from the left-hand menu, and select your database on the SQL databases page.
In Azure portal, select SQL databases from the left-hand menu, and select your database on the SQL databases page. On the Overview page, select Set server firewall. The Firewall settings page for the database server opens.
On the Overview page, select Set server firewall. The Firewall settings page for the database server opens.
Step 3: Connect to the database and use Transact-SQL to create a database firewall rule
Database-level firewall rules can only be configured using Transact-SQL (T-SQL) statements, and only after you've configured a server-level firewall rule.
To setup a database-level firewall rule: In Object Explorer, right-click the database and select New Query.EXECUTE sp_set_database_firewall_rule N'Example DB Rule','0.0.0.4','0.0.0.4'; On the toolbar, select Execute to create the firewall rule. References:
In Object Explorer, right-click the database and select New Query.EXECUTE sp_set_database_firewall_rule N'Example DB Rule','0.0.0.4','0.0.0.4'; On the toolbar, select Execute to create the firewall rule. References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-security-tutorial
NEW QUESTION 6
A company has a SaaS solution that uses Azure SQL Database with elastic pools. The solution contains a dedicated database for each customer organization. Customer organizations have peak usage at different periods during the year.
You need to implement the Azure SQL Database elastic pool to minimize cost. Which option or options should you configure?
- A. Number of transactions only
- B. eDTUs per database only
- C. Number of databases only
- D. CPU usage only
- E. eDTUs and max data size
Answer: E
Explanation:
The best size for a pool depends on the aggregate resources needed for all databases in the pool. This involves determining the following: Maximum resources utilized by all databases in the pool (either maximum DTUs or maximum vCores depending on your choice of resourcing model). Maximum storage bytes utilized by all databases in the pool.
Maximum resources utilized by all databases in the pool (either maximum DTUs or maximum vCores depending on your choice of resourcing model). Maximum storage bytes utilized by all databases in the pool.
Note: Elastic pools enable the developer to purchase resources for a pool shared by multiple databases to accommodate unpredictable periods of usage by individual databases. You can configure resources for the pool based either on the DTU-based purchasing model or the vCore-based purchasing model.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-pool
NEW QUESTION 7
You manage a process that performs analysis of daily web traffic logs on an HDInsight cluster. Each of 250 web servers generates approximately gigabytes (GB) of log data each day. All log data is stored in a single folder in Microsoft Azure Data Lake Storage Gen 2.
You need to improve the performance of the process.
Which two changes should you make? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
- A. Combine the daily log files for all servers into one file
- B. Increase the value of the mapreduce.map.memory parameter
- C. Move the log files into folders so that each day’s logs are in their own folder
- D. Increase the number of worker nodes
- E. Increase the value of the hive.tez.container.size parameter
Answer: AC
Explanation:
A: Typically, analytics engines such as HDInsight and Azure Data Lake Analytics have a per-file overhead. If you store your data as many small files, this can negatively affect performance. In general, organize your data into larger sized files for better performance (256MB to 100GB in size). Some engines and applications might have trouble efficiently processing files that are greater than 100GB in size.
C: For Hive workloads, partition pruning of time-series data can help some queries read only a subset of the data which improves performance.
Those pipelines that ingest time-series data, often place their files with a very structured naming for files and folders. Below is a very common example we see for data that is structured by date:
DataSetYYYYMMDDdatafile_YYYY_MM_DD.tsv
Notice that the datetime information appears both as folders and in the filename. References:
https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-performance-tuning-guidance
NEW QUESTION 8
You develop data engineering solutions for a company.
A project requires analysis of real-time Twitter feeds. Posts that contain specific keywords must be stored and processed on Microsoft Azure and then displayed by using Microsoft Power BI. You need to implement the solution.
Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Step 1: Create an HDInisght cluster with the Spark cluster type Step 2: Create a Jyputer Notebook
Step 3: Create a table
The Jupyter Notebook that you created in the previous step includes code to create an hvac table. Step 4: Run a job that uses the Spark Streaming API to ingest data from Twitter
Step 5: Load the hvac table into Power BI Desktop
You use Power BI to create visualizations, reports, and dashboards from the Spark cluster data. References:
https://acadgild.com/blog/streaming-twitter-data-using-spark
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-use-with-data-lake-store
NEW QUESTION 9
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging.
Solution: Create an Azure Automation runbook to copy events. Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION 10
Your company manages on-premises Microsoft SQL Server pipelines by using a custom solution.
The data engineering team must implement a process to pull data from SQL Server and migrate it to Azure Blob storage. The process must orchestrate and manage the data lifecycle.
You need to configure Azure Data Factory to connect to the on-premises SQL Server database.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Step 1: Create a virtual private network (VPN) connection from on-premises to Microsoft Azure.
You can also use IPSec VPN or Azure ExpressRoute to further secure the communication channel between your on-premises network and Azure.
Azure Virtual Network is a logical representation of your network in the cloud. You can connect an
on-premises network to your virtual network by setting up IPSec VPN (site-to-site) or ExpressRoute (private peering).
Step 2: Create an Azure Data Factory resource. Step 3: Configure a self-hosted integration runtime.
You create a self-hosted integration runtime and associate it with an on-premises machine with the SQL Server database. The self-hosted integration runtime is the component that copies data from the SQL Server database on your machine to Azure Blob storage.
Note: A self-hosted integration runtime can run copy activities between a cloud data store and a data store in a private network, and it can dispatch transform activities against compute resources in an on-premises network or an Azure virtual network. The installation of a self-hosted integration runtime needs on an on-premises machine or a virtual machine (VM) inside a private network.
References:
https://docs.microsoft.com/en-us/azure/data-factory/tutorial-hybrid-copy-powershell
NEW QUESTION 11
A company is designing a hybrid solution to synchronize data and on-premises Microsoft SQL Server database to Azure SQL Database.
You must perform an assessment of databases to determine whether data will move without compatibility issues.
You need to perform the assessment. Which tool should you use?
- A. Azure SQL Data Sync
- B. SQL Vulnerability Assessment (VA)
- C. SQL Server Migration Assistant (SSMA)
- D. Microsoft Assessment and Planning Toolkit
- E. Data Migration Assistant (DMA)
Answer: E
Explanation:
The Data Migration Assistant (DMA) helps you upgrade to a modern data platform by detecting compatibility issues that can impact database functionality in your new version of SQL Server or Azure SQL Database. DMA recommends performance and reliability improvements for your target environment and allows you to move your schema, data, and uncontained objects from your source server to your target server.
References:
https://docs.microsoft.com/en-us/sql/dma/dma-overview
NEW QUESTION 12
You are developing the data platform for a global retail company. The company operates during normal working hours in each region. The analytical database is used once a week for building sales projections.
Each region maintains its own private virtual network.
Building the sales projections is very resource intensive are generates upwards of 20 terabytes (TB) of data. Microsoft Azure SQL Databases must be provisioned. Database provisioning must maximize performance and minimize cost The daily sales for each region must be stored in an Azure SQL Database instance Once a day, the data for all regions must be loaded in an analytical Azure SQL Database instance You need to provision Azure SQL database instances.
The daily sales for each region must be stored in an Azure SQL Database instance Once a day, the data for all regions must be loaded in an analytical Azure SQL Database instance You need to provision Azure SQL database instances.
How should you provision the database instances? To answer, drag the appropriate Azure SQL products to the correct databases. Each Azure SQL product may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Azure SQL Database elastic pools
SQL Database elastic pools are a simple, cost-effective solution for managing and scaling multiple databases that have varying and unpredictable usage demands. The databases in an elastic pool are on a single Azure
SQL Database server and share a set number of resources at a set price. Elastic pools in Azure SQL Database enable SaaS developers to optimize the price performance for a group of databases within a prescribed budget while delivering performance elasticity for each database.
Box 2: Azure SQL Database Hyperscale
A Hyperscale database is an Azure SQL database in the Hyperscale service tier that is backed by the Hyperscale scale-out storage technology. A Hyperscale database supports up to 100 TB of data and provides high throughput and performance, as well as rapid scaling to adapt to the workload requirements. Scaling is transparent to the application – connectivity, query processing, and so on, work like any other SQL database.
NEW QUESTION 13
You are designing a new Lambda architecture on Microsoft Azure. The real-time processing layer must meet the following requirements: Ingestion: Receive millions of events per second Act as a fully managed Platform-as-a-Service (PaaS) solution
Receive millions of events per second Act as a fully managed Platform-as-a-Service (PaaS) solution  Integrate with Azure Functions
Integrate with Azure Functions
Stream processing: Process on a per-job basis Provide seamless connectivity with Azure services Use a SQL-based query language
Analytical data store: Act as a managed service Use a document store Provide data encryption at rest
You need to identify the correct technologies to build the Lambda architecture using minimal effort. Which technologies should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Azure Event Hubs
This portion of a streaming architecture is often referred to as stream buffering. Options include Azure Event Hubs, Azure IoT Hub, and Kafka.
NEW QUESTION 14
You develop data engineering solutions for a company.
A project requires the deployment of data to Azure Data Lake Storage.
You need to implement role-based access control (RBAC) so that project members can manage the Azure Data Lake Storage resources.
Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Assign Azure AD security groups to Azure Data Lake Storage.
- B. Configure end-user authentication for the Azure Data Lake Storage account.
- C. Configure service-to-service authentication for the Azure Data Lake Storage account.
- D. Create security groups in Azure Active Directory (Azure AD) and add project members.
- E. Configure access control lists (ACL) for the Azure Data Lake Storage account.
Answer: ADE
NEW QUESTION 15
An application will use Microsoft Azure Cosmos DB as its data solution. The application will use the Cassandra API to support a column-based database type that uses containers to store items.
You need to provision Azure Cosmos DB. Which container name and item name should you use? Each correct answer presents part of the solutions.
NOTE: Each correct answer selection is worth one point.
- A. table
- B. collection
- C. graph
- D. entities
- E. rows
Answer: AE
Explanation:
Depending on the choice of the API, an Azure Cosmos item can represent either a document in a collection, a row in a table or a node/edge in a graph. The following table shows the mapping between API-specific entities to an Azure Cosmos item:
An Azure Cosmos container is specialized into API-specific entities as follows:
References:
https://docs.microsoft.com/en-us/azure/cosmos-db/databases-containers-items
NEW QUESTION 16
You are a data engineer implementing a lambda architecture on Microsoft Azure. You use an open-source big data solution to collect, process, and maintain data. The analytical data store performs poorly.
You must implement a solution that meets the following requirements: Provide data warehousing Reduce ongoing management activities Deliver SQL query responses in less than one second
Deliver SQL query responses in less than one second
You need to create an HDInsight cluster to meet the requirements. Which type of cluster should you create?
- A. Interactive Query
- B. Apache Hadoop
- C. Apache HBase
- D. Apache Spark
Answer: D
Explanation:
Lambda Architecture with Azure:
Azure offers you a combination of following technologies to accelerate real-time big data analytics: Azure Cosmos DB, a globally distributed and multi-model database service. Apache Spark for Azure HDInsight, a processing framework that runs large-scale data analytics applications.The Spark to Azure Cosmos DB Connector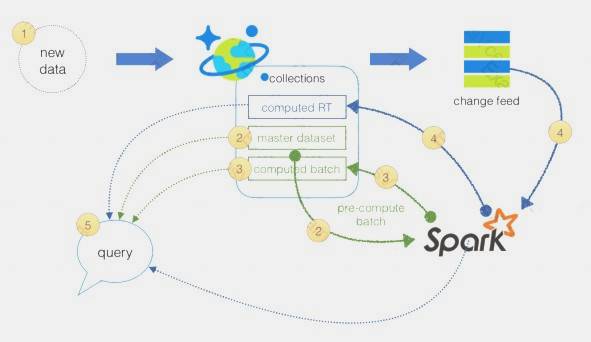
Note: Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch processing and stream processing methods, and minimizing the latency involved in querying big data.
References:
https://sqlwithmanoj.com/2021/02/16/what-is-lambda-architecture-and-what-azure-offers-with-its-new-cosmos-
NEW QUESTION 17
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals.
You develop a data ingestion process that will import data to a Microsoft Azure SQL Data Warehouse. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account. You need to toad the data from the Azure Data Lake Gen 2 storage account into the Azure SQL Data
Warehouse.
Solution:
1. Create an external data source pointing to the Azure storage account
2. Create an external file format and external table using the external data source
3. Load the data using the INSERT…SELECT statement
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
You load the data using the CREATE TABLE AS SELECT statement. References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-load-from-azure-data-lake-store
NEW QUESTION 18
You plan to create a new single database instance of Microsoft Azure SQL Database.
The database must only allow communication from the data engineer’s workstation. You must connect directly to the instance by using Microsoft SQL Server Management Studio.
You need to create and configure the Database. Which three Azure PowerShell cmdlets should you use to develop the solution? To answer, move the appropriate cmdlets from the list of cmdlets to the answer area and arrange them in the correct order.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Step 1: New-AzureSqlServer Create a server.
Step 2: New-AzureRmSqlServerFirewallRule
New-AzureRmSqlServerFirewallRule creates a firewall rule for a SQL Database server. Can be used to create a server firewall rule that allows access from the specified IP range. Step 3: New-AzureRmSqlDatabase
Example: Create a database on a specified server
PS C:>New-AzureRmSqlDatabase -ResourceGroupName "ResourceGroup01" -ServerName "Server01"
-DatabaseName "Database01
References:
https://docs.microsoft.com/en-us/azure/sql-database/scripts/sql-database-create-and-configure-database-powersh
NEW QUESTION 19
You are the data engineer tor your company. An application uses a NoSQL database to store data. The database uses the key-value and wide-column NoSQL database type.
Developers need to access data in the database using an API.
You need to determine which API to use for the database model and type.
Which two APIs should you use? Each correct answer presents a complete solution. NOTE: Each correct selection s worth one point.
- A. Table API
- B. MongoDB API
- C. Gremlin API
- D. SQL API
- E. Cassandra API
Answer: BE
Explanation:
B: Azure Cosmos DB is the globally distributed, multimodel database service from Microsoft for mission-critical applications. It is a multimodel database and supports document, key-value, graph, and columnar data models.
E: Wide-column stores store data together as columns instead of rows and are optimized for queries over large datasets. The most popular are Cassandra and HBase.
References:
https://docs.microsoft.com/en-us/azure/cosmos-db/graph-introduction https://www.mongodb.com/scale/types-of-nosql-databases
NEW QUESTION 20
You develop data engineering solutions for a company. An application creates a database on Microsoft Azure. You have the following code:
Which database and authorization types are used? To answer, select the appropriate option in the answer area.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Azure Cosmos DB
The DocumentClient.CreateDatabaseAsync(Database, RequestOptions) method creates a database resource as an asychronous operation in the Azure Cosmos DB service.
Box 2: Master Key
Azure Cosmos DB uses two types of keys to authenticate users and provide access to its data and resources: Master Key, Resource Tokens
Master keys provide access to the all the administrative resources for the database account. Master keys: Provide access to accounts, databases, users, and permissions. Cannot be used to provide granular access to containers and documents. Are created during the creation of an account. Can be regenerated at any time.
NEW QUESTION 21
A company builds an application to allow developers to share and compare code. The conversations, code snippets, and links shared by people in the application are stored in a Microsoft Azure SQL Database instance. The application allows for searches of historical conversations and code snippets.
When users share code snippets, the code snippet is compared against previously share code snippets by using a combination of Transact-SQL functions including SUBSTRING, FIRST_VALUE, and SQRT. If a match is found, a link to the match is added to the conversation.
Customers report the following issues: Delays occur during live conversations A delay occurs before matching links appear after code snippets are added to conversations
You need to resolve the performance issues.
Which technologies should you use? To answer, drag the appropriate technologies to the correct issues. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.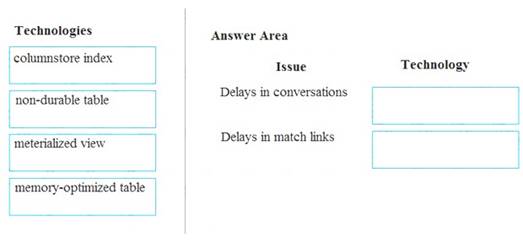
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: memory-optimized table
In-Memory OLTP can provide great performance benefits for transaction processing, data ingestion, and transient data scenarios.
Box 2: materialized view
To support efficient querying, a common solution is to generate, in advance, a view that materializes the data in a format suited to the required results set. The Materialized View pattern describes generating prepopulated views of data in environments where the source data isn't in a suitable format for querying, where generating a suitable query is difficult, or where query performance is poor due to the nature of the data or the data store.
These materialized views, which only contain data required by a query, allow applications to quickly obtain the information they need. In addition to joining tables or combining data entities, materialized views can include the current values of calculated columns or data items, the results of combining values or executing transformations on the data items, and values specified as part of the query. A materialized view can even be optimized for just a single query.
References:
https://docs.microsoft.com/en-us/azure/architecture/patterns/materialized-view
NEW QUESTION 22
......
Recommend!! Get the Full DP-200 dumps in VCE and PDF From Certleader, Welcome to Download: https://www.certleader.com/DP-200-dumps.html (New 88 Q&As Version)