Certleader offers free demo for DP-201 exam. "Designing an Azure Data Solution", also known as DP-201 exam, is a Microsoft Certification. This set of posts, Passing the Microsoft DP-201 exam, will help you answer those questions. The DP-201 Questions & Answers covers all the knowledge points of the real exam. 100% real Microsoft DP-201 exams and revised by experts!
Free demo questions for Microsoft DP-201 Exam Dumps Below:
NEW QUESTION 1
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company is developing a solution to manage inventory data for a group of automotive repair shops. The solution will use Azure SQL Data Warehouse as the data store.
Shops will upload data every 10 days.
Data corruption checks must run each time data is uploaded. If corruption is detected, the corrupted data must be removed.
You need to ensure that upload processes and data corruption checks do not impact reporting and analytics processes that use the data warehouse.
Proposed solution: Configure database-level auditing in Azure SQL Data Warehouse and set retention to 10 days.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
Instead, create a user-defined restore point before data is uploaded. Delete the restore point after data corruption checks complete.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
NEW QUESTION 2
You are designing an Azure Data Factory pipeline for processing data. The pipeline will process data that is stored in general-purpose standard Azure storage.
You need to ensure that the compute environment is created on-demand and removed when the process is completed.
Which type of activity should you recommend?
- A. Databricks Python activity
- B. Data Lake Analytics U-SQL activity
- C. HDInsight Pig activity
- D. Databricks Jar activity
Answer: C
Explanation:
The HDInsight Pig activity in a Data Factory pipeline executes Pig queries on your own or on-demand HDInsight cluster.
References:
https://docs.microsoft.com/en-us/azure/data-factory/transform-data-using-hadoop-pig
NEW QUESTION 3
A company stores large datasets in Azure, including sales transactions and customer account information. You must design a solution to analyze the data. You plan to create the following HDInsight clusters:
You need to ensure that the clusters support the query requirements.
Which cluster types should you recommend? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Interactive Query
Choose Interactive Query cluster type to optimize for ad hoc, interactive queries. Box 2: Hadoop
Choose Apache Hadoop cluster type to optimize for Hive queries used as a batch process.
Note: In Azure HDInsight, there are several cluster types and technologies that can run Apache Hive queries. When you create your HDInsight cluster, choose the appropriate cluster type to help optimize performance for your workload needs.
For example, choose Interactive Query cluster type to optimize for ad hoc, interactive queries. Choose Apache Hadoop cluster type to optimize for Hive queries used as a batch process. Spark and HBase cluster types can also run Hive queries.
References:
https://docs.microsoft.com/bs-latn-ba/azure/hdinsight/hdinsight-hadoop-optimize-hive-query?toc=%2Fko-kr%2
NEW QUESTION 4
You need to design the SensorData collection.
What should you recommend? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Eventual
Traffic data insertion rate must be maximized.
Sensor data must be stored in a Cosmos DB named treydata in a collection named SensorData
With Azure Cosmos DB, developers can choose from five well-defined consistency models on the consistency spectrum. From strongest to more relaxed, the models include strong, bounded staleness, session, consistent prefix, and eventual consistency.
Box 2: License plate
This solution reports on all data related to a specific vehicle license plate. The report must use data from the SensorData collection.
References:
https://docs.microsoft.com/en-us/azure/cosmos-db/consistency-levels
NEW QUESTION 5
You need to recommend a backup strategy for CONT_SQL1 and CONT_SQL2. What should you recommend?
- A. Use AzCopy and store the data in Azure.
- B. Configure Azure SQL Database long-term retention for all databases.
- C. Configure Accelerated Database Recovery.
- D. Use DWLoader.
Answer: B
Explanation:
Scenario: The database backups have regulatory purposes and must be retained for seven years.
NEW QUESTION 6
You need to recommend an Azure SQL Database service tier. What should you recommend?
- A. Business Critical
- B. General Purpose
- C. Premium
- D. Standard
- E. Basic
Answer: C
Explanation:
The data engineers must set the SQL Data Warehouse compute resources to consume 300 DWUs. Note: There are three architectural models that are used in Azure SQL Database: General Purpose/Standard Business Critical/Premium Hyperscale
General Purpose/Standard Business Critical/Premium Hyperscale
NEW QUESTION 7
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure SQL Database that will use elastic pools. You plan to store data about customers in a table. Each record uses a value for CustomerID.
You need to recommend a strategy to partition data based on values in CustomerID. Proposed Solution: Separate data into customer regions by using vertical partitioning. Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
Vertical partitioning is used for cross-database queries. Instead we should use Horizontal Partitioning, which also is called charding.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-query-overview
NEW QUESTION 8
You need to recommend an Azure SQL Database pricing tier for Planning Assistance. Which pricing tier should you recommend?
- A. Business critical Azure SQL Database single database
- B. General purpose Azure SQL Database Managed Instance
- C. Business critical Azure SQL Database Managed Instance
- D. General purpose Azure SQL Database single database
Answer: B
Explanation:
Azure resource costs must be minimized where possible.
Data used for Planning Assistance must be stored in a sharded Azure SQL Database. The SLA for Planning Assistance is 70 percent, and multiday outages are permitted.
NEW QUESTION 9
You are designing a solution for a company. You plan to use Azure Databricks. You need to recommend workloads and tiers to meet the following requirements: Provide managed clusters for running production jobs. Provide persistent clusters that support auto-scaling for analytics processes. Provide role-based access control (RBAC) support for Notebooks.
Provide managed clusters for running production jobs. Provide persistent clusters that support auto-scaling for analytics processes. Provide role-based access control (RBAC) support for Notebooks.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Data Engineering Only
Box 2: Data Engineering and Data Analytics Box 3: Standard
Box 4: Data Analytics only Box 5: Premium
Premium required for RBAC. Data Analytics Premium Tier provide interactive workloads to analyze data collaboratively with notebooks
References:
https://azure.microsoft.com/en-us/pricing/details/databricks/
NEW QUESTION 10
You are designing a data processing solution that will run as a Spark job on an HDInsight cluster. The solution will be used to provide near real-time information about online ordering for a retailer.
The solution must include a page on the company intranet that displays summary information. The summary information page must meet the following requirements: Display a summary of sales to date grouped by product categories, price range, and review scope. Display sales summary information including total sales, sales as compared to one day ago and sales as compared to one year ago. Reflect information for new orders as quickly as possible. You need to recommend a design for the solution.
What should you recommend? To answer, select the appropriate configuration in the answer area.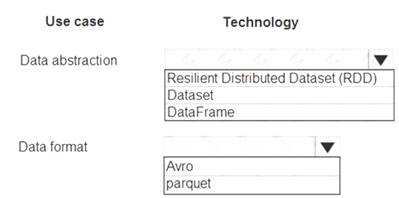
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: DataFrame
DataFrames
Best choice in most situations.
Provides query optimization through Catalyst. Whole-stage code generation.
Direct memory access.
Low garbage collection (GC) overhead.
Not as developer-friendly as DataSets, as there are no compile-time checks or domain object programming. Box 2: parquet
The best format for performance is parquet with snappy compression, which is the default in Spark 2.x. Parquet stores data in columnar format, and is highly optimized in Spark.
NEW QUESTION 11
A company manufactures automobile parts. The company installs IoT sensors on manufacturing machinery. You must design a solution that analyzes data from the sensors.
You need to recommend a solution that meets the following requirements: Data must be analyzed in real-time.
Data queries must be deployed using continuous integration. Data must be visualized by using charts and graphs.
Data must be available for ETL operations in the future. The solution must support high-volume data ingestion.
Which three actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Use Azure Analysis Services to query the dat
- B. Output query results to Power BI.
- C. Configure an Azure Event Hub to capture data to Azure Data Lake Storage.
- D. Develop an Azure Stream Analytics application that queries the data and outputs to Power B
- E. Use AzureData Factory to deploy the Azure Stream Analytics application.
- F. Develop an application that sends the IoT data to an Azure Event Hub.
- G. Develop an Azure Stream Analytics application that queries the data and outputs to Power B
- H. Use AzurePipelines to deploy the Azure Stream Analytics application.
- I. Develop an application that sends the IoT data to an Azure Data Lake Storage container.
Answer: BCD
NEW QUESTION 12
You are designing an application. You plan to use Azure SQL Database to support the application.
The application will extract data from the Azure SQL Database and create text documents. The text documents will be placed into a cloud-based storage solution. The text storage solution must be accessible from an SMB network share.
You need to recommend a data storage solution for the text documents. Which Azure data storage type should you recommend?
- A. Queue
- B. Files
- C. Blob
- D. Table
Answer: B
Explanation:
Azure Files enables you to set up highly available network file shares that can be accessed by using the standard Server Message Block (SMB) protocol.
References:
https://docs.microsoft.com/en-us/azure/storage/common/storage-introduction https://docs.microsoft.com/en-us/azure/storage/tables/table-storage-overview
NEW QUESTION 13
You have a Windows-based solution that analyzes scientific data. You are designing a cloud-based solution that performs real-time analysis of the data.
You need to design the logical flow for the solution.
Which two actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Send data from the application to an Azure Stream Analytics job.
- B. Use an Azure Stream Analytics job on an edge devic
- C. Ingress data from an Azure Data Factory instance and build queries that output to Power BI.
- D. Use an Azure Stream Analytics job in the clou
- E. Ingress data from the Azure Event Hub instance and build queries that output to Power BI.
- F. Use an Azure Stream Analytics job in the clou
- G. Ingress data from an Azure Event Hub instance and build queries that output to Azure Data Lake Storage.
- H. Send data from the application to Azure Data Lake Storage.
- I. Send data from the application to an Azure Event Hub instance.
Answer: CF
Explanation:
Stream Analytics has first-class integration with Azure data streams as inputs from three kinds of resources: Azure Event Hubs
Azure IoT Hub Azure Blob storage References:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-define-inputs
NEW QUESTION 14
You are designing an Azure Databricks cluster that runs user-defined local processes. You need to recommend a cluster configuration that meets the following requirements:
• Minimize query latency.
• Reduce overall costs.
• Maximize the number of users that can run queries on the cluster at the same time. Which cluster type should you recommend?
- A. Standard with Autoscaling
- B. High Concurrency with Auto Termination
- C. High Concurrency with Autoscaling
- D. Standard with Auto Termination
Answer: C
Explanation:
High Concurrency clusters allow multiple users to run queries on the cluster at the same time, while minimizing query latency. Autoscaling clusters can reduce overall costs compared to a statically-sized cluster.
References:
https://docs.azuredatabricks.net/user-guide/clusters/create.html https://docs.azuredatabricks.net/user-guide/clusters/high-concurrency.html#high-concurrency https://docs.azuredatabricks.net/user-guide/clusters/terminate.html https://docs.azuredatabricks.net/user-guide/clusters/sizing.html#enable-and-configure-autoscaling
NEW QUESTION 15
STION NO: 5 HOTSPOT
You need to design the authentication and authorization methods for sensors.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Sensor data must be stored in a Cosmos DB named treydata in a collection named SensorData Sensors must have permission only to add items to the SensorData collection
Box 1: Resource Token
Resource tokens provide access to the application resources within a Cosmos DB database.
Enable clients to read, write, and delete resources in the Cosmos DB account according to the permissions they've been granted.
Box 2: Cosmos DB user
You can use a resource token (by creating Cosmos DB users and permissions) when you want to provide access to resources in your Cosmos DB account to a client that cannot be trusted with the master key.
References:
https://docs.microsoft.com/en-us/azure/cosmos-db/secure-access-to-data
NEW QUESTION 16
A company purchases loT devices to monitor manufacturing machinery. The company uses an loT appliance to communicate with the loT devices.
The company must be able to monitor the devices in real-time. You need to design the solution.
What should you recommend?
- A. Azure Stream Analytics cloud job using Azure PowerShell
- B. Azure Analysis Services using Azure Portal
- C. Azure Data Factory instance using Azure Portal
- D. Azure Analysis Services using Azure PowerShell
Answer: D
NEW QUESTION 17
You need to design a solution to meet the SQL Server storage requirements for CONT_SQL3. Which type of disk should you recommend?
- A. Standard SSD Managed Disk
- B. Premium SSD Managed Disk
- C. Ultra SSD Managed Disk
Answer: C
Explanation:
CONT_SQL3 requires an initial scale of 35000 IOPS.
The following table provides a comparison of ultra solid-state-drives (SSD) (preview), premium SSD, standard SSD, and standard hard disk drives (HDD) for managed disks to help you decide what to use.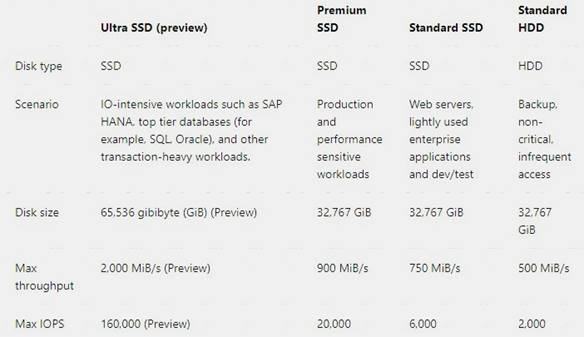
References:
https://docs.microsoft.com/en-us/azure/virtual-machines/windows/disks-types
NEW QUESTION 18
You design data engineering solutions for a company.
A project requires analytics and visualization of large set of data. The project has the following requirements: Notebook scheduling Cluster automation Power BI Visualization
You need to recommend the appropriate Azure service. Which Azure service should you recommend?
- A. Azure Batch
- B. Azure Stream Analytics
- C. Azure ML Studio
- D. Azure Databricks
- E. Azure HDInsight
Answer: D
Explanation:
A databrick job is a way of running a notebook or JAR either immediately or on a scheduled basis.
Azure Databricks has two types of clusters: interactive and job. Interactive clusters are used to analyze data collaboratively with interactive notebooks. Job clusters are used to run fast and robust automated workloads using the UI or API.
You can visualize Data with Azure Databricks and Power BI Desktop.
References:
https://docs.azuredatabricks.net/user-guide/clusters/index.html https://docs.azuredatabricks.net/user-guide/jobs.html
NEW QUESTION 19
You need to recommend a solution for storing customer data. What should you recommend?
- A. Azure SQL Data Warehouse
- B. Azure Stream Analytics
- C. Azure Databricks
- D. Azure SQL Database
Answer: C
Explanation:
From the scenario:
Customer data must be analyzed using managed Spark clusters.
All cloud data must be encrypted at rest and in transit. The solution must support: parallel processing of customer data.
References:
https://www.microsoft.com/developerblog/2021/01/18/running-parallel-apache-spark-notebook-workloads-on-a
NEW QUESTION 20
You need to recommend a solution for storing the image tagging data. What should you recommend?
- A. Azure File Storage
- B. Azure Cosmos DB
- C. Azure Blob Storage
- D. Azure SQL Database
- E. Azure SQL Data Warehouse
Answer: C
Explanation:
Image data must be stored in a single data store at minimum cost.
Note: Azure Blob storage is Microsoft's object storage solution for the cloud. Blob storage is optimized for storing massive amounts of unstructured data. Unstructured data is data that does not adhere to a particular data model or definition, such as text or binary data.
Blob storage is designed for: Serving images or documents directly to a browser. Storing files for distributed access. Streaming video and audio. Writing to log files. Storing data for backup and restore, disaster recovery, and archiving. Storing data for analysis by an on-premises or Azure-hosted service.
Serving images or documents directly to a browser. Storing files for distributed access. Streaming video and audio. Writing to log files. Storing data for backup and restore, disaster recovery, and archiving. Storing data for analysis by an on-premises or Azure-hosted service.
References:
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blobs-introduction
NEW QUESTION 21
You need to design the vehicle images storage solution. What should you recommend?
- A. Azure Media Services
- B. Azure Premium Storage account
- C. Azure Redis Cache
- D. Azure Cosmos DB
Answer: B
Explanation:
Premium Storage stores data on the latest technology Solid State Drives (SSDs) whereas Standard Storage stores data on Hard Disk Drives (HDDs). Premium Storage is designed for Azure Virtual Machine workloads which require consistent high IO performance and low latency in order to host IO intensive workloads like OLTP, Big Data, and Data Warehousing on platforms like SQL Server, MongoDB, Cassandra, and others. With Premium Storage, more customers will be able to lift-and-shift demanding enterprise applications to the cloud.
Scenario: Traffic sensors will occasionally capture an image of a vehicle for debugging purposes. You must optimize performance of saving/storing vehicle images.
The impact of vehicle images on sensor data throughout must be minimized. References:
https://azure.microsoft.com/es-es/blog/introducing-premium-storage-high-performance-storage-for-azure-virtual
NEW QUESTION 22
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these
questions will not appear in the review screen.
You are designing an HDInsight/Hadoop cluster solution that uses Azure Data Lake Gen1 Storage. The solution requires POSIX permissions and enables diagnostics logging for auditing.
You need to recommend solutions that optimize storage.
Proposed Solution: Ensure that files stored are larger than 250MB. Does the solution meet the goal?
- A. Yes
- B. No
Answer: A
Explanation:
Depending on what services and workloads are using the data, a good size to consider for files is 256 MB or greater. If the file sizes cannot be batched when landing in Data Lake Storage Gen1, you can have a separate compaction job that combines these files into larger ones.
Note: POSIX permissions and auditing in Data Lake Storage Gen1 comes with an overhead that becomes apparent when working with numerous small files. As a best practice, you must batch your data into larger files versus writing thousands or millions of small files to Data Lake Storage Gen1. Avoiding small file sizes can have multiple benefits, such as:
Lowering the authentication checks across multiple files Reduced open file connections
Faster copying/replication
Fewer files to process when updating Data Lake Storage Gen1 POSIX permissions References:
https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-best-practices
NEW QUESTION 23
You plan to migrate data to Azure SQL Database.
The database must remain synchronized with updates to Microsoft Azure and SQL Server. You need to set up the database as a subscriber.
What should you recommend?
- A. Azure Data Factory
- B. SQL Server Data Tools
- C. Data Migration Assistant
- D. SQL Server Agent for SQL Server 2021 or later
- E. SQL Server Management Studio 17.9.1 or later
Answer: E
Explanation:
To set up the database as a subscriber we need to configure database replication. You can use SQL Server Management Studio to configure replication. Use the latest versions of SQL Server Management Studio in order to be able to use all the features of Azure SQL Database.
References:
https://www.sqlshack.com/sql-server-database-migration-to-azure-sql-database-using-sql-server-transactionalrep
NEW QUESTION 24
......
Recommend!! Get the Full DP-201 dumps in VCE and PDF From Certleader, Welcome to Download: https://www.certleader.com/DP-201-dumps.html (New 74 Q&As Version)